La Inteligencia Artificial se adapta al lenguaje del sector legal
El Instituto de Ingeniería del Conocimiento lanza el primer modelo de lenguaje en español para el sector legal, mejorando la clasificación de documentos y la detección de entidades

Dentro del Procesamiento del Lenguaje Natural (PLN) moderno, los modelos de lenguaje se han convertido en los cimientos de los sistemas avanzados de tratamiento del texto. Un modelo de lenguaje es una red neuronal artificial capaz de analizar grandes volúmenes de texto escrito para aprender la estructura con la que se presentan las palabras de un idioma determinado.
Ya nos suena el nombre de algunos modelos del lenguaje inglés, como BERT, RoBERTa, T5 o GPT-3. Estos han llegado a ser capaces en los últimos años de generar noticias automáticamente, pero también de mejorar la efectividad en otras tareas de PLN como la traducción automática o la recuperación de información en base a preguntas formuladas por un humano.
Ahora el Instituto de Ingeniería del Conocimiento (IIC) trabaja en un proyecto de investigación para explotar y crear modelos de lenguaje en español: RigoBERTa. Y uno de los primeros logros ha sido el desarrollo del primer modelo de lenguaje en español adaptado al sector legal.
¿Cómo se adapta un modelo del lenguaje al sector legal?
Un punto importante a tener en cuenta en el desarrollo de sistemas de Procesamiento del Lenguaje Natural es el dominio del lenguaje en el que se aplican. Y es que los modelos de lenguaje generalistas, que suelen crearse a partir de corpus de textos de páginas web, noticias, obras literarias o webs enciclopédicas como Wikipedia, pueden no ajustarse del todo a los términos y la jerga de sectores especializados como el médico, el financiero o el legal.
Por ello, se ha desarrollado una metodología para reajustar los modelos de lenguaje existentes y adaptarlos a los diferentes dominios con nuevos textos del sector en cuestión. Por ejemplo, para la creación de ese primer modelo de lenguaje en español para el sector legal, han partido de BETO, el modelo general del español desarrollado por la Universidad de Chile.
Este se ha reentrenado con un gran corpus legal-administrativo de más de 500 millones de palabras, que ha sido recopilado de fuentes abiertas y curado por su equipo de lingüistas computacionales, garantizando la calidad de los textos.
Resultados de RigoBERTa en el sector legal
Contar con un modelo de lenguaje adaptado al ámbito legal tiene ventajas si se pone en práctica con dos de los principales problemas del sector: la clasificación de documentos y la detección de entidades nombradas en el texto (personas y organizaciones). Una vez reajustado el modelo del español general, los primeros resultados muestran cómo se gana en acierto cuando se usa la versión especializada en el sector legal.
Además, tras el lanzamiento del modelo del IIC, se liberó de manera abierta el modelo RoBERTalex, desarrollado bajo el paraguas del Plan de Impulso de las Tecnologías del Lenguaje y también enfocado al dominio legal. Probados ambos, el primero sigue alcanzando cotas de rendimiento más elevadas.
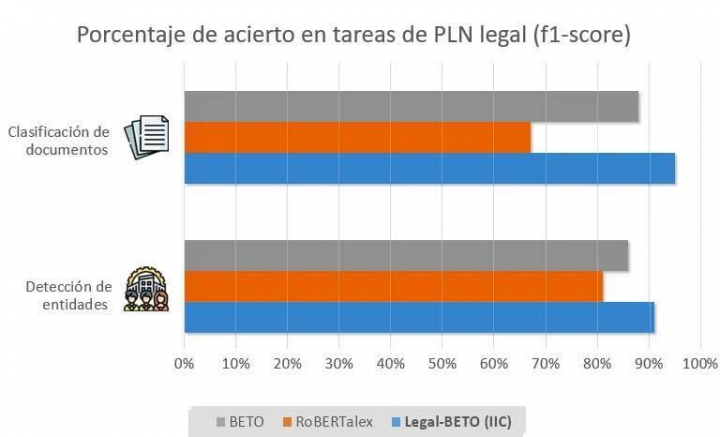
Dentro del proyecto de investigación RigoBERTa, se va a seguir trabajando en el desarrollo de modelos de lenguaje del español general, así como en modelos adaptados a diferentes dominios.













